
-
游戏联运系统
-
手游联运系统
千款游戏任意运营
-
页游联运系统
PC官网、CPS系统…等
-
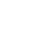
H5游戏联运系统
快速启动,无须下载在线即玩
-
游戏联运系统(海外版)
支持多国语言,多种国际支付
-
行业对比
帮您甄选最优质的产品和服务
标准版
-
标准版联运系统
全新 UI 界面,内含多种玩法
-
PC官网
炫酷视觉,多套风格模版可换
-
游戏盒子APP
新功能上线,快来下载体验吧
-
后台管理系统
自定义分成,多等级权限
-
推广员系统
低成本管理,数据可视化
-
推广助手APP
高效发展玩家,充值实时掌控
-
标准盒子PC端
谷歌IE双核,可领微端奖励
-
千款热门游戏
手游、H5、页游全都有
星耀版
-
星耀版联运系统
豪华配置,功能强大
-
PC官网
全新 UI 界面,功能模块重新划分
-
游戏盒子APP
游戏社区化运营,新版强势来袭
-
后台管理系统
游戏、玩家、资金一站管理
-
推广员系统
五级分销,分成比例自定
-
推广助手APP
移动办公,发展玩家更方便
-
招商加盟系统
一键贴牌,快速发展加盟商
-
星耀盒子PC端
全新UI上线,引流新利器
-
千款热门游戏
包含多款大厂S级游戏
发行系统
-
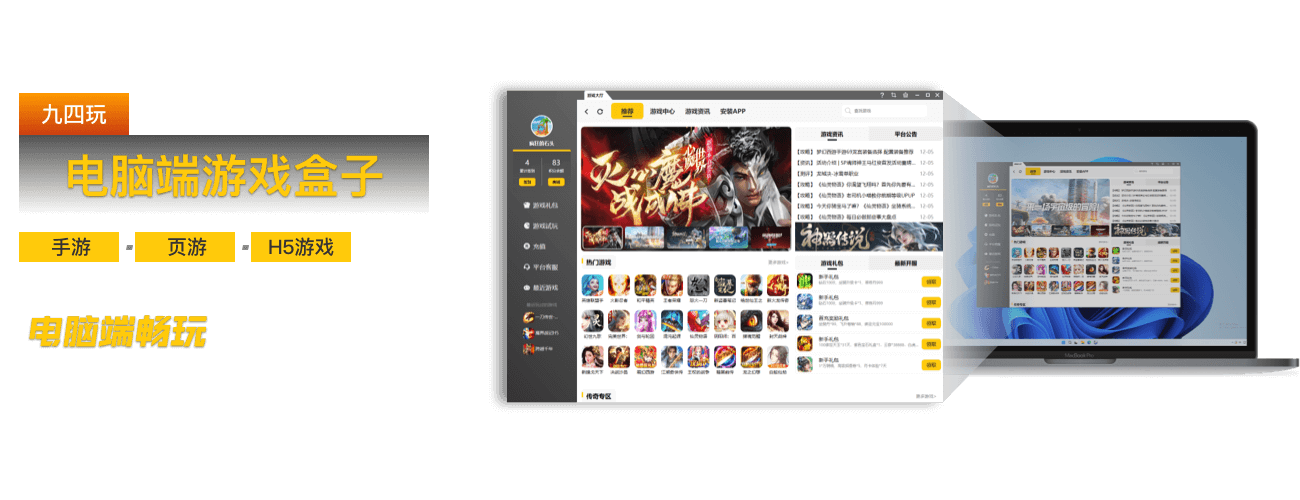
游戏发行系统
低成本快速搭建,一键分发
-
SDK4.0发行版
兼容性强,低门槛融入下级SDK
-
渠道端后台
自定义分成,多等级权限
-
发行端后台
低成本管理,数据可视化
联运SDK
-
游戏联运SDK
登录注册、充值、防沉迷...等
-
简版联运SDK
功能自定义、开放式...等
-
海外联运SDK
多语言、海外充值通道...等
-
-
游戏陪玩系统
-
游戏陪玩系统
变现模式多样(订单、礼物、招商加盟)
-
陪玩PC官网
自适应所有终端机型,引流更方便
-
陪玩APP
在线点单陪玩,语音聊天室...等
-
陪玩后台管理系统
一站式管理陪玩技师/订单/玩家数据...
游戏直播系统
-
游戏直播系统
观看流畅,高清画质
-
游戏开播助手
原生开发,快速开播,数据互通
游戏社交系统
-
游戏社区系统
私域化运营,提升产品黏性
-
游戏圈子系统
打造社区氛围,维护玩家情感
-
IM 即时通讯系统
私信、支持文字、图片、短视频等
产品插件
-
聊天工具包
网络推广,聊天营销必备工具
-
短视频工具包
短视频营销必备工具,快速引流
-
广告转化追踪
转化追踪的基础上增加数据监控
-
三方短信接口
用于对接第三方短信接口
-
省钱卡
提高消费动机,促进用户付费
-
一元买号
使账号流通,增加游戏活跃度
-
转游福利
等价兑换游戏币,新游引流利器
-
公众号折扣充值
使用公众号一键充值,快捷方便
-
大转盘(抽奖)
抽奖营销活动,增加玩家留存率
-
自定义专题页
让您的游戏平台与众不同
-
推广小程序
官网小程序,推广更方便
-
查看更多
-
 游戏库
游戏库
 解决方案
解决方案
 厂商入驻
厂商入驻
 行业对比
行业对比




















































 九四玩·北京开源纵横网络科技有限公司
九四玩·北京开源纵横网络科技有限公司 
